Drahten
Search Service
Responsible for actions related to searching information from the internet on topics offered by the application
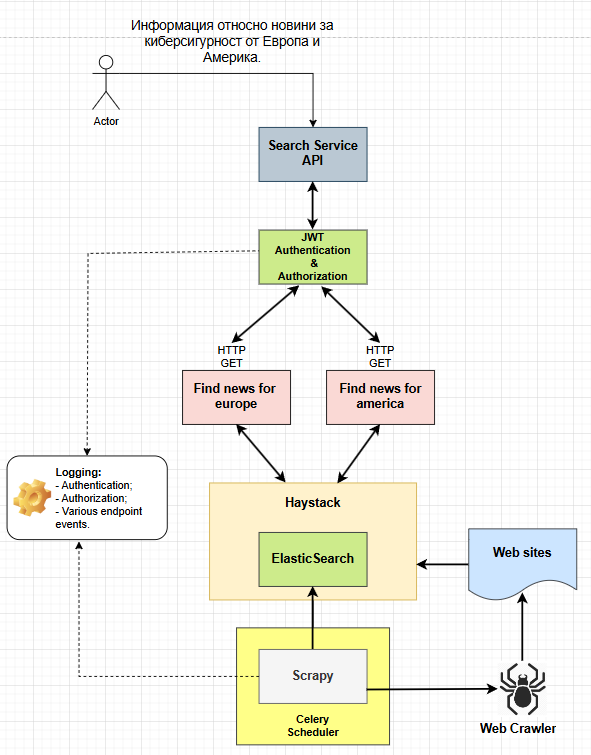
The components of the diagram have the following meaning
-
Actor - This can be a user or a process from the application. The user or process requests information. In the diagram, an example request for “Cybersecurity news from Europe and America” is shown. The request is forwarded to the Search Service API, which then returns a response containing the appropriate HTTP code and information (if found).
-
Search Service API - A web API providing various endpoints. The diagram shows two such endpoints: “Find news for Europe” and “Find news for America,” responding to HTTP GET requests for information requested by third parties/users. When a request is made to one of the provided endpoints, it is forwarded to Haystack, where it is processed and sent to ElasticSearch. ElasticSearch returns a response in JSON format to the party/user who made the request to the Search Service API.
-
JWT Authentication & Authorization - A layer for authentication and authorization, requiring JWT tokens to authenticate the party/user requesting access to protected resources from the Search Service API.
-
Web Crawler - An internet bot that systematically browses web pages to extract information.
-
ElasticSearch - Used for searching and storing information extracted by Web Crawler processes.
-
Haystack - Acts as a wrapper for ElasticSearch to build capabilities for semantic search. Together, Haystack and ElasticSearch form a search engine for semantic information retrieval. The information passed to Haystack by Web Crawler processes is processed using techniques such as removing unnecessary white spaces, tokenization (e.g., splitting text by words or sentences), etc. After processing, the information is stored in ElasticSearch. Information to be retrieved from ElasticSearch through an HTTP request by third parties/users to Haystack is either forwarded directly to ElasticSearch (if the request does not require semantic information retrieval) or processed by Haystack using techniques such as retrieving information from ElasticSearch that matches the request using the TF-IDF algorithm. The result is then passed to a transformer model that provides the final result for the request. The result is returned in JSON format to the party/user who made the request to the Search Service API.
-
Scrapy - Used for extracting information from websites through Web Crawler processes.
-
Celery Scheduler - Used to execute Scrapy at predefined intervals.
-
Web sites - Web pages from which the Web Crawler extracts information.
-
Logging - Used for recording information about various events in the Search service. This information is forwarded to the Log Collection Service.
A diagram describing the operation of the information collection blocks from the internet (Scrapy and Celery Scheduler) and information search (Haystack and ElasticSearch)
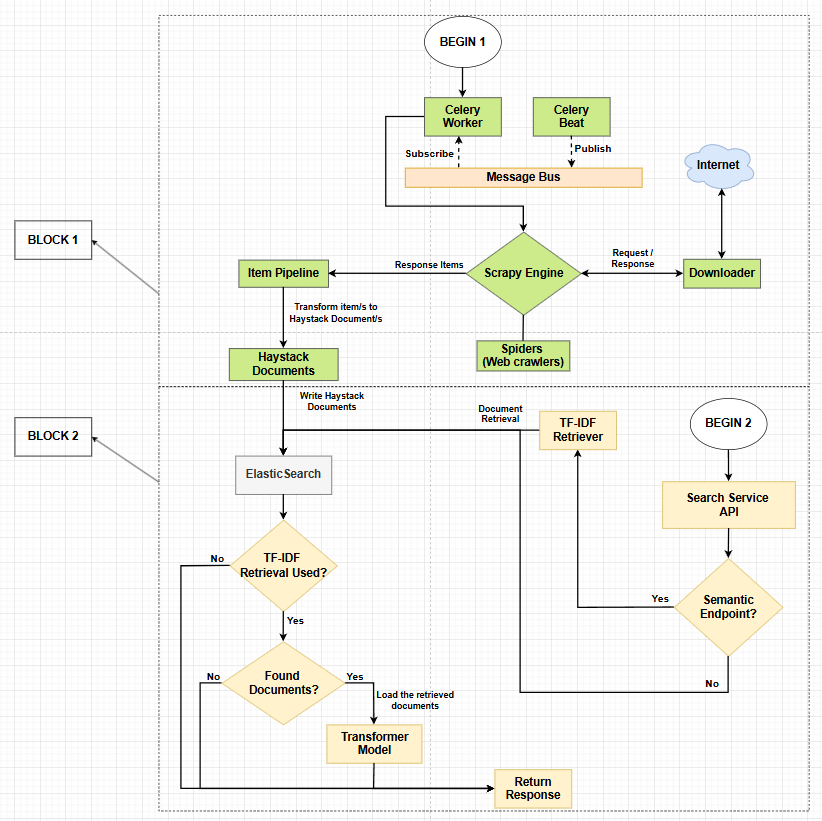
The components of the diagram have the following meaning
Block 1
Describes the operation of the information collection blocks from the internet (Scrapy and Celery Scheduler). The components of this block are colored green and have the following meaning:
- Celery Beat - A task scheduler that publishes messages to the Message Bus to initiate Web Crawling processes.
- Celery Worker - A process that starts tasks by receiving requests for their initiation from the Message Bus.
- Message Bus - A message broker implemented using RabbitMQ. It facilitates communication between the Celery Beat process, which publishes messages, and the Celery Worker process, which receives messages.
- Spiders - A specific type of web robot used to navigate and process web pages to extract information.
- Item Pipeline - A component that includes a series of steps for processing items extracted by Spiders. After extraction, the information is passed to the Item Pipeline, where it is processed through several components that execute sequentially. Each component is a Python class implementing a method to perform actions on the items, such as validating the scanned information, checking for duplicates, and storing the scanned information in a database (in this case, ElasticSearch).
- Scrapy Engine - Controls the data flow between all Scrapy components. It manages the processing of information through the Item Pipeline and passes responses from Spiders.
- Downloader - A component that manages the retrieval of web pages and delivers responses to the Scrapy Engine. This is where HTTP requests are made, based on requests generated by Spiders. This component is also responsible for handling various HTTP aspects such as retries, redirects, and cookies.
Block 2
Describes the operation of the information search blocks (Haystack and ElasticSearch). The components of this block are colored yellow and have the following meaning:
- Search Service API - Represents the Django REST framework.
- TF-IDF Retriever - A component used to retrieve documents from ElasticSearch. The TF-IDF Retriever scans information from a specific index in ElasticSearch and returns a set of documents deemed relevant to a given query. It uses the TF-IDF algorithm, which evaluates how important a word is concerning a specific document in the specified ElasticSearch index. TF measures how often a term appears in a document. The more frequently a term appears in a document, the higher its frequency. IDF measures the importance of a term in a set of documents. If a term appears in many documents, the term is not significant (the importance of the term concerning the corpus is small) and will have a lower IDF value. Conversely, if the term does not appear in many documents, it will be more significant and will have a higher IDF value. The result: TF-IDF is calculated by multiplying the TF and IDF values. The TF-IDF Retriever uses this result to rank documents from the specified Elasticsearch index concerning how relevant they are to the input query.
- Transformer Model - Represents ROBERTA transformer model. This model is better than BERT for document retrieval due to the following reasons:
- It is trained on a dataset that is more than 10 times larger than that used for BERT, allowing it to process and “understand” language with a higher degree of accuracy.
- It performs better than BERT on various natural language processing tasks;
- It uses a different tokenizer - BPE (the same as GPT-2). This tokenizer has a larger vocabulary (50000 vs. 30000 words for BERT). This can lead to better handling of different natural languages.